SRE兼バックエンドエンジニアの高良です。
今回は弊社でのSLOを策定するまでの経緯を紹介します。
SLOが必要になった経緯
弊社エンジニアチームでは、今期からの組織計画の一環として、各種KPIの策定が必要とされていました。
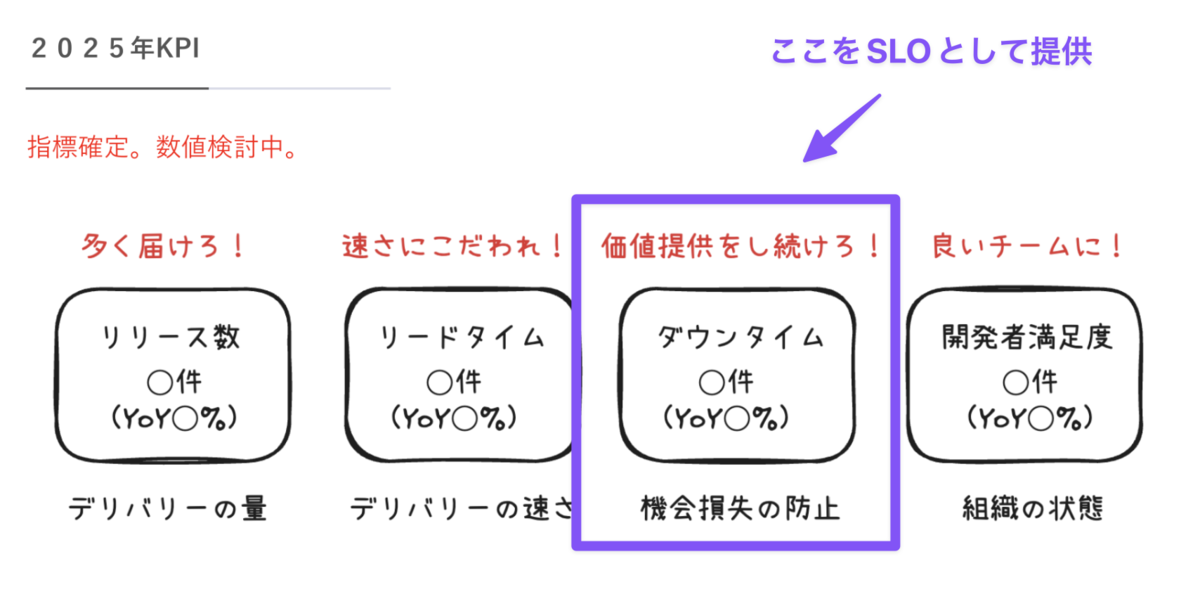
これまでのダウンタイムはどう取り扱っていた?
弊社では障害発生時の対応フローとしてPagerdutyによるオンコール体制は整っており、障害レポートの作成や再発防止策の策定なども含めた、他チームへの共有も毎回行われていました。
しかし都度都度の対応はこなしていたものの、トータルで見ると、自分たちのサービスはどのくらいの安定稼働できているのか? といった、合計値に基づいた稼働実績の分析は出来ていないのが実情でした。
そのため、今回のKPI策定をきっかけに、弊社でもダウンタイム・アップタイムの定義を正式に設けることにしました。
どうやってSLI/SLOを決めたか
そもそもSLI/SLOとは下記のような概念です。
SLI(サービスレベル指標)とは「Service Level Indicator」の略であり、サービスの稼働状況を数値化した指標のことを表します。 また、そのSLIはSLO(サービスレベル目標)を達成しているか測定するための指標になります。例えば、月間99.95%利用可能であると定めた場合、SLIがその値を超える必要があるということになるということです。 【用語解説】SLI(サービスレベル指標)とは? | sreake.com | 株式会社スリーシェイク
SLO導入にあたり、まず直面したのが「どの指標をSLI(Service Level Indicator)として採用すべきか?」という問題でした。
いくつか候補は挙がりましたが、最初に採用することになったのはレスポンスタイムでした。これは、弊社における障害の多くが外形監視のアラート発報を契機として認識されているという背景があったためです。
すなわち「外形監視で一定時間レスポンスが返らなければ障害扱いになる」という運用が既に浸透していたため、SLIでも “外形監視でのレスポンスタイム”を使うという扱いで当面は運用し、後々各サービスの状況により細かくチューニングしていく、という判断になりました。
「障害って何?」から始めるSLI/SLO設計
SLIを決めるにあたって、最初に出たのは「ユーザーの体感と一致していることが大事だよね」という意見でした。
たとえば、ELBの平均レスポンスタイムをSLIにしてしまうと、その前段のキャッシュサーバがダウンしていても、ELBが元気なら問題なしと判定されてしまいます。
逆に、アプリやDBが落ちていたとしても、キャッシュがうまくカバーしていて、ユーザーが気づいていないなら、それって本当に「障害」と呼べるんだろうか?
そんな会話を通じて、「ユーザーが不満に感じた瞬間をどう検知するか」という軸に自然と収束していきました。
SLI候補の洗い出しと比較
SLO導入にあたり、いくつかのSLI候補案を検討しました。
それぞれの案にメリット・デメリットがあり、理想と現実のバランスをどう取るかが論点となりました。
① スプレッドシートによる手動集計
🔍 概要
障害発生後にアラートの鳴動時間を目視で確認し、手動でスプレッドシートに記録。
アップタイムやSLOは関数で計算する方式です。
✅ メリット
- 実装コストがかからず、すぐに運用を開始できる
- 小規模・試験的な導入には向いている
⚠️ デメリット
- 記録が手作業のため、人的負荷・ヒューマンエラーのリスクがある
- 記録漏れや粒度のバラつきが発生しやすい
② ELBのレスポンスタイムを活用した計測
🔍 概要
AWS ELBの p99 または p95 レスポンスタイムをモニタリングし、
設定したしきい値(例:p99 > 2秒)を超過した場合にダウンタイムと見なす方法です。
✅ メリット
- DatadogとAWSが連携済みであれば、すぐにデータ取得・可視化が可能
- 運用の自動化が比較的容易
⚠️ デメリット
- FastlyやCloudFrontなどキャッシュ経由の構成では、ユーザーの体感との乖離が起きやすい
- 構成によっては有効な指標にならない場合がある
③ Datadog Synthetics による外形監視
🔍 概要
Datadog Syntheticsという外形監視機能で指定したエンドポイントを定期的に監視し、
レスポンス遅延や失敗を「ダウンタイム」として扱います。
✅ メリット
- 弊社で現在利用しているMackerelの外形監視と類似の運用が可能
- DatadogのSLO機能と直接連携できる
- Terraformでコード化でき、再利用性が高い
⚠️ デメリット
- コストが高い
- 1エンドポイント × 1分間隔の監視で月額約4,000円(2025年時点)
- 5サービス監視する場合は月額約20,000円
- ユースケースとしては理想的だが、現時点ではコストに見合わないと判断
④ Fastlyのメトリクスを活用
🔍 概要
Datadogで収集しているFastlyのメトリクス(例:hits_time, miss_time など)をもとに、
ユーザー体感に近い指標を近似的に算出する方法です。
✅ メリット
- Fastlyが最前段にある構成が多く、ユーザーの体感を反映しやすい
- Terraformで再利用性が高く、他サービスへの展開も容易
⚠️ デメリット
- 平均レスポンスタイムが直接取得できないため、hits,hits_time,miss,miss_timeなどのメトリクスを使って近似値を算出することになる
✅ 決定案:④ Fastlyのメトリクスを採用
最終的に、下記の理由により④ Fastlyのメトリクスを活用する案 を採用することにしました。
- Fastlyがアプリケーションの最前段に配置されている構成が多く、 ユーザーの体感に近い稼働状況をモニタリングできる
- Datadogとの連携で計測する際も追加コストがかからない
- Terraformによる定義の再利用も可能で、他サービスへの横展開も見据えやすい
運用への組み込み
上述の指標をSLOとして策定後、部署の定例ミーティングにおける確認フローの一部として組み込みました。
今後も定例での確認を通してSLIの数値を継続的にモニタリングし、サービスの安定稼働を「感覚」ではなく「事実」として捉えることで、 改善判断の材料として活用していける体制を目指します。
今後の全社的な活用に向けて
今後は、策定したSLOを全社共通で利用できる指標として活用していくことを目指しています。
SREやエンジニアだけでなく、他の開発・事業チームともこの数値を共有し、
- 障害対応の優先順位付け
- 技術的負債の返済タイミング
- 改善投資(予算・リソース配分)に関する合意形成
上記のような対話のベースとなる状態を作っていきたいと考えています。
個人の所感
SLIやSLOといった数値はあくまで手段であり、ただ決めて終わりではなく常にサービスの品質向上に繋がるように意識が必要だと感じました。
今後も運用が形骸化しないよう、数値の背景にある体験や判断とセットで扱う文化を作っていけたらと思います!